היי סתיו! אחלה שאלות.
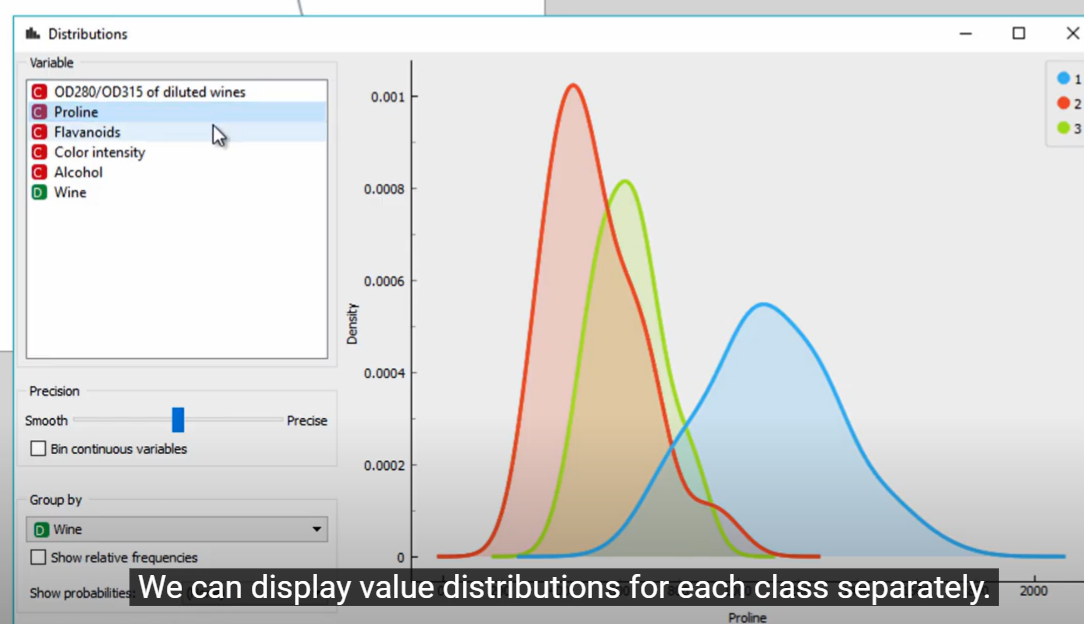
ככלל, התשובה היא כן. פיצ'ר שמראה פחות חפיפה בחלוקה לפי משתנה המטרה, יהיה בעל ערך גבוה יותר מבחינתנו כשנרצה לסווג. לדוגמא אם נרצה לסווג צמחים לשיחים/עצים, הגובה שלהם יתן הפרדה די טובה וכנראה שנרצה להשתמש בו (יותר מצבע העלים לפחות.).
זה לא אומר אגב, שהפיצ'רים האחרים חסרי ערך. לפעמים שילוב של כמה פיצ'רים שכל אחד בפני עצמו נראה בעל ערך נמוך, דווקא נותן כושר סיווג טוב. בזיהוי תמונות למשל, אף פיקסל בפני עצמו הוא לא בעל ערך רב בזיהוי התמונה, אבל אפשר לשלב את הערכים שלהם ליצירת מודלים די מתוחכמים.
לגבי הערכים החסרים, התשובה קצת מורכבת. דאטה כמעט אף פעם לא נקי לגמרי, וכמעט תמיד יש ערכים חסרים. אם יש לנו מזל, אז הערכים החסרים הם מיעוט ולא ישפיעו יותר מדי, אבל אם 90% מהנתונים הם זבל, כנראה שלא נוכל להפיק מהם יותר מדי. במקרה שלנו באמת מדובר במיעוט, ואין צורך לבחור את העמודה לפי מספר הערכים החסרים. בכל מקרה כדאי לחשוב איך עדיף להתמודד עם זה. יש כמה כמה דרכים ולכל אחת יש את היתרונות והחסרונות שלה.